如果我们要使用spark,最好是根据自己的环境把源码编译一次。而且我们已经有了编译hadoop的经验,这个做起来比编译hadoop简单哈。
环境准备
硬件环境:2核2线程 8G内存 40G硬盘
Linux环境:CentOS 6.5
jdk版本:jdk1.8
scala版本:2.12.8
maven版本:apache-maven-3.6.0
Hadoop版本:hadoop-2.6.0-cdh5.7.0
git版本:1.7.1
下载spark源码
前往github上面的spark源码地址https://github.com/apache/spark/ 这个是目前最新的代码,我们要选择一个版本,点击branch,选择master最近的一个版本
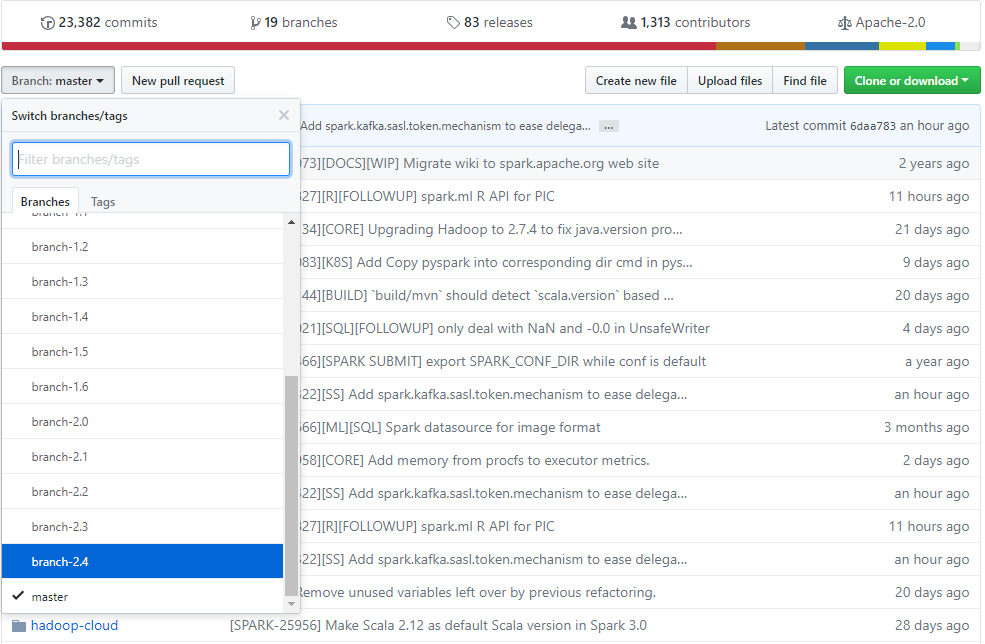
如上图所示,我们选择的版本就是2.4了,点击Clone or download按钮,我们下载源码包spark-branch-2.4.zip
上传spark源码
将我们得到的zip上传到我们虚拟机上面
1 | su - hadoop |
解压spark源码
1 | unzip spark-branch-2.4.zip -D ../source |
修改pom文件
1 | cd ~/source/spark-branch-2.4 |
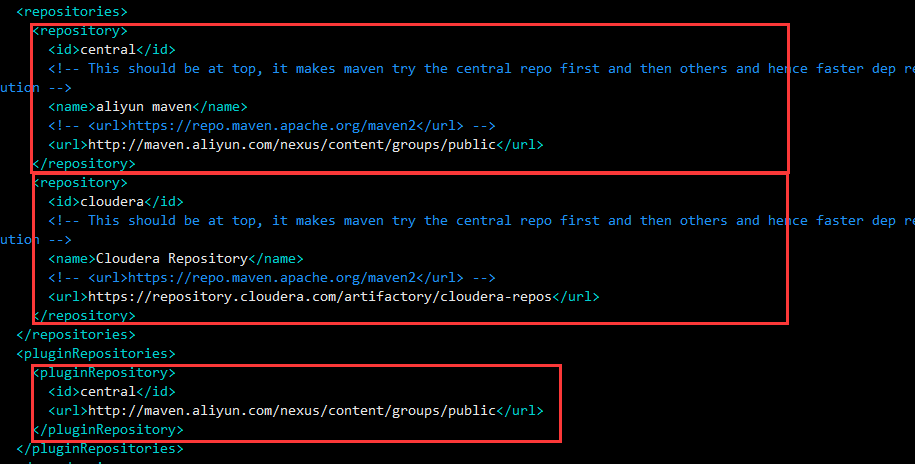
1.修改maven仓库地址,为了提速我们把repositories替换成如下配置(原来的可以删除掉)
1 | <repositories> |
2.插件地址也替换掉,找到pluginRepositories
1 | <pluginRepositories> |
修改make-distribution.sh
为了提速需要将判断版本的语句注释,我们直接写入版本信息
1 | vi ~/source/spark-branch-2.4/dev/make-distribution.sh |
1 | VERSION=2.4.0 |
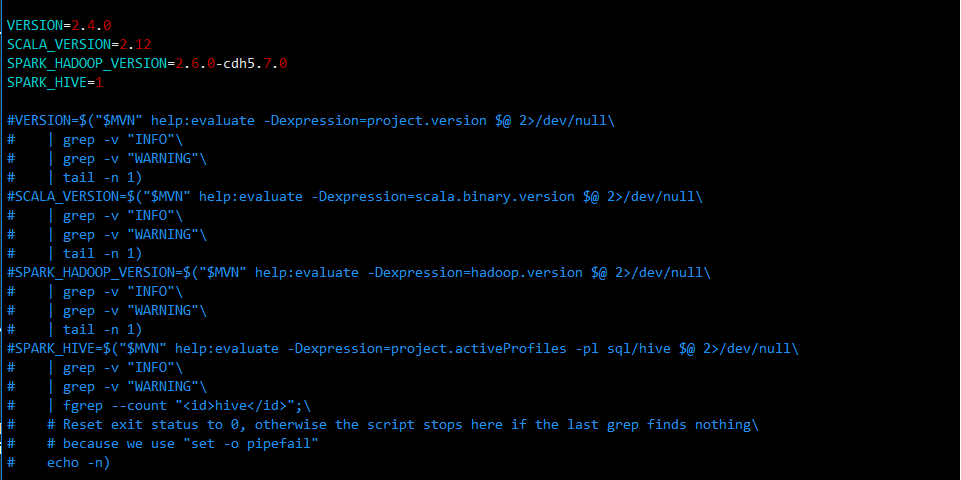
至此我们完成所有配置修改
编译spark
1 | cd ~/source/spark-branch-2.4 |
输入完这个命令,就开始编译了。一开始有个语句,我很不安
编译的时候,我会在这个步骤卡得比较久
cpu飚的得很高

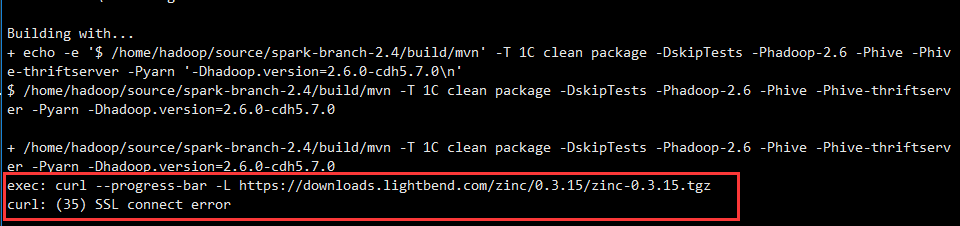
错误1
好的,没错。失败了。我果然很有先见之明
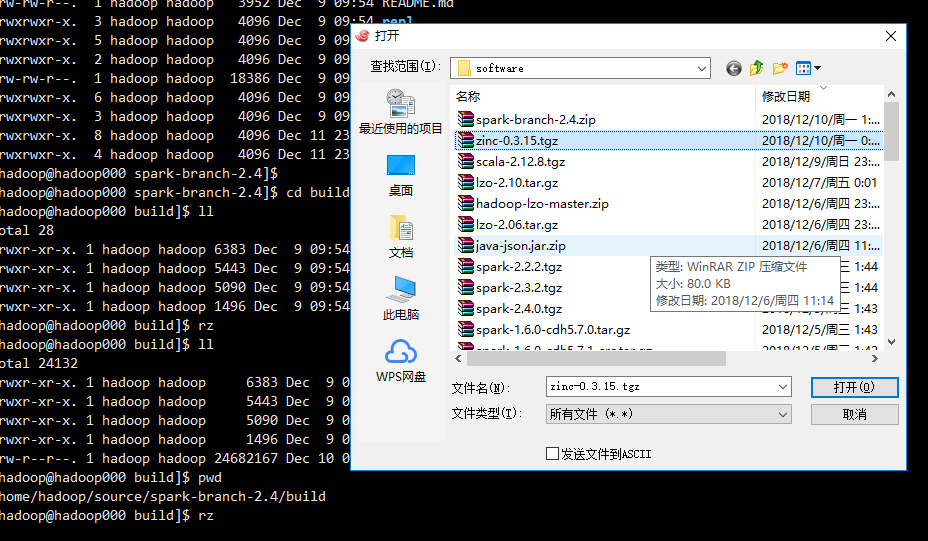
我手工去下载zinc-0.3.15.tgz包,错误提示的地址果然下载不了,我把地址里面https改成http又愉快的下载起来了
1 | cd /home/hadoop/source/spark-branch-2.4/build |
然后重新跑起来
1 | cd /home/hadoop/source/spark-branch-2.4 |
希望这次能没有问题,我们去喝杯咖啡压压惊

这些代码好像写得好多warning~,看着不是很舒服
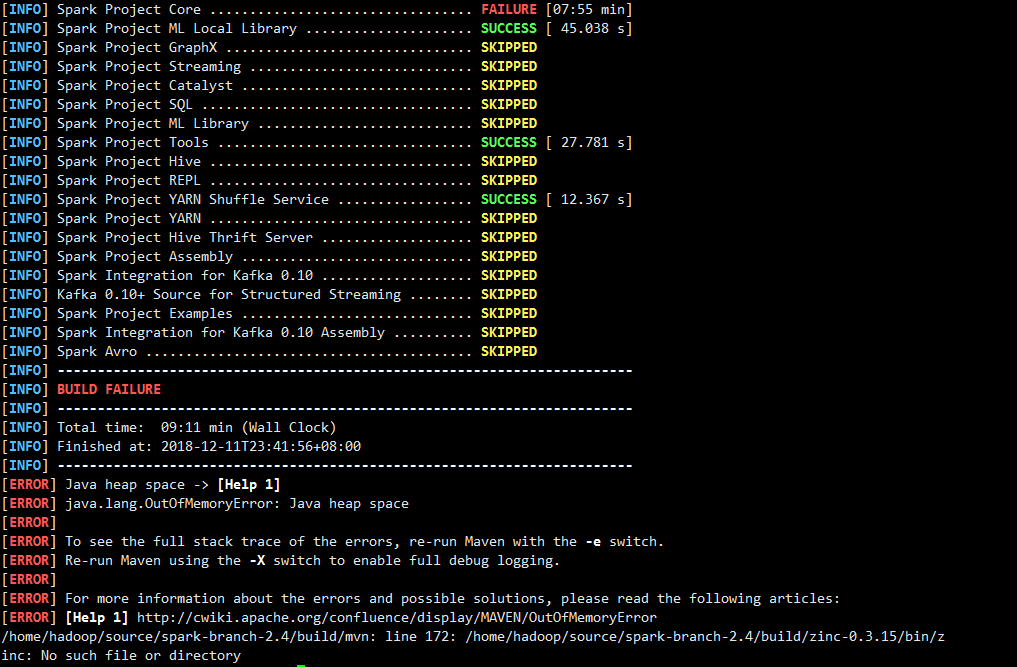
完成
突然眼前飘过一片绿
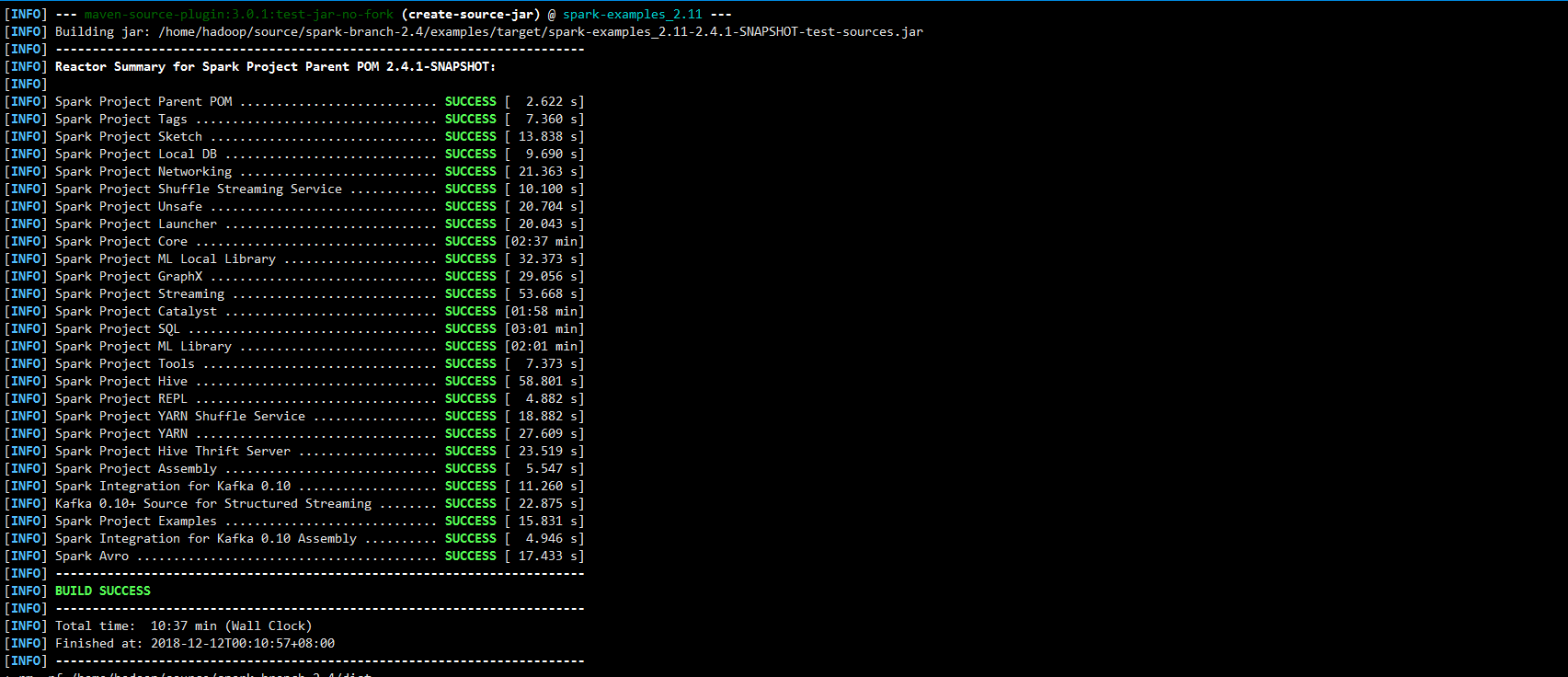
没错,编译成功了~
1 | ll |
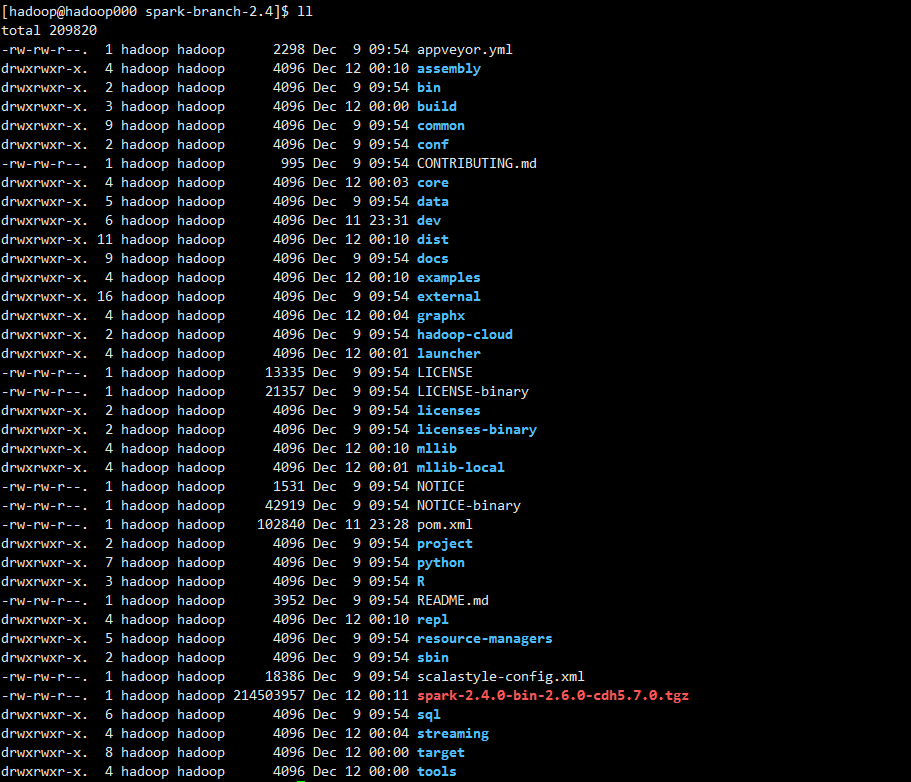
看到这个tgz,至此我们的编译完成!