what’s Spark
Apache Spark™ is a unified analytics engine for large-scale data processing.
Spark是用于大规模数据处理的统一分析引擎。
Speed
Run workloads 100x faster.
Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
Spark是运行在内存上的高速的计算引擎,会比Hadoop快100多倍
Ease of Use
1 | df = spark.read.json("logs.json") |
大部分应用都是用Java、Scala、Python、R。Spark还提供了80个高级算子,是我们容易搭建起分布式APP
Generality
支持Spark SQL,Streaming 和 complex analytics.
Run Everywhere
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
Spark可以跑在Yarn. Mesos,Kubernetes 独立集群或者云服务。它能访问各种数据源。
Spark生态圈
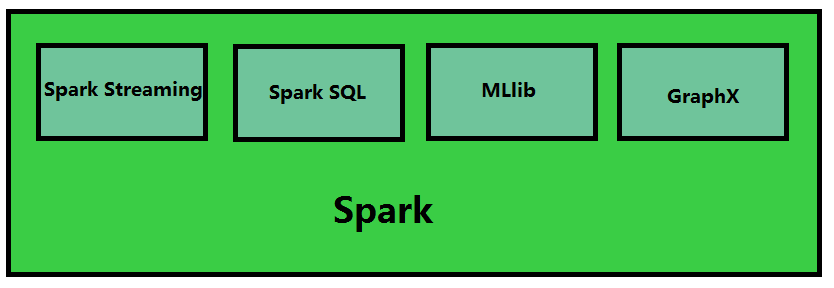
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
官网这段话很好说明了,spark提供了4种高级工具,Spark SQL、GraphX、MLlib和Spark Streaming,
Spark常用术语
Application
Application:应用。可以认为是多次批量计算组合起来的过程,在物理上可以表现为你写的程序包+部署配置。应用的概念类似于计算机中的程序,它只是一个蓝本,尚没有运行起来。
RDD
RDD:Resilient Distributed Datasets,弹性分布式数据集。RDD即是计算模型里的一个概念,也是你编程时用到的一种类。一个RDD可以认为是spark在执行分布式计算时的一批相同来源、相同结构、相同用途的数据集,这个数据集可能被切割成多个分区,分布在不同的机器上,无论如何,这个数据集被称为一个RDD。在编程时,RDD对象就对应了这个数据集,并且RDD对象被当作一个数据操作的基本单位。比如,对某个RDD对象进行map操作,其实就相当于将数据集中的每个分区的每一条数据进行了map映射。
Partition
Partition:分区。一个RDD在物理上被切分为多个Partition,即数据分区,这些Partition可以分布在不同的节点上。Partition是Spark计算任务的基本处理单位,决定了并行计算的粒度,而Partition中的每一条Record为基本处理对象。例如对某个RDD进行map操作,在具体执行时是由多个并行的Task对各自分区的每一条记录进行map映射。
RDD Graph
RDD Graph:RDD组成的DAG(有向无环图)。RDD是不可变的,一个RDD经过某种操作后,会生成一个新的RDD。这样说来,一个Application中的程序,其内容基本上都是对各种RDD的操作,从源RDD,经过各种计算,产生中间RDD,最后生成你想要的RDD并输出。这个过程中的各个RDD,会构成一个有向无环图。
Lineage
Lineage:血统。RDD这个概念本身包含了这种信息“由哪个父类RDD经过哪种操作得到”。所以某个RDD可以通过不断寻找父类,找到最原始的那个RDD。这条继承路径就认为是RDD的血统。
Dependency
对RDD的Transformation或Action操作,让RDD产生了父子依赖关系(事实上,Transformation或Action操作生成的中间RDD也存在依赖关系),这种依赖分为宽依赖和窄依赖两种:
- NarrowDependency (窄依赖)
parent RDD中的每个Partition最多被child RDD中的一个Partition使用。让RDD产生窄依赖的操作可以称为窄依赖操作,如map、union。 - WideDependency (或ShuffleDependency,宽依赖)
parent RDD中的每个Partition被child RDD中的多个Partition使用,这时会依据Record的key进行数据重组,这个过程即为Shuffle(洗牌)。让RDD产生宽依赖的操作可以称为宽依赖操作,如reduceByKey, groupByKey。
Spark根据用户Application中的RDD的转换和行动,生成RDD之间的依赖关系,RDD之间的计算链构成了RDD的血统(Lineage),同时也生成了逻辑上的DAG(有向无环图)。每一个RDD都可以根据其依赖关系一级一级向前回溯重新计算,这便是Spark实现容错的一种手段:RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
Job
在一个Application中,以Action为划分边界的Spark批处理作业。前面提到,Spark采用惰性机制,对RDD的创建和转换并不会立即执行,只有在遇到第一个Action时才会生成一个Job,然后统一调度执行。一个Job包含N个Transformation和1个Action。
Shuffle
有一部分Transformation或Action会让RDD产生宽依赖,这样过程就像是将父RDD中所有分区的Record进行了“洗牌”(Shuffle),数据被打散重组,如属于Transformation操作的join,以及属于Action操作的reduce等,都会产生Shuffle。
Stage
一个Job中,以Shuffle为边界划分出的不同阶段。每个阶段包含一组可以被串行执行的窄依赖或宽依赖操作:
用户提交的计算任务是一个由RDD构成的DAG,如果RDD在转换的时候需要做Shuffle,那么这个Shuffle的过程就将这个DAG分为了不同的阶段(即Stage)。由于Shuffle的存在,不同的Stage是不能并行计算的,因为后面Stage的计算需要前面Stage的Shuffle的结果。
在对Job中的所有操作划分Stage时,一般会按照倒序进行,即从Action开始,遇到窄依赖操作,则划分到同一个执行阶段,遇到宽依赖操作,则划分一个新的执行阶段,且新的阶段为之前阶段的parent,然后依次类推递归执行。child Stage需要等待所有的parent Stage执行完之后才可以执行,这时Stage之间根据依赖关系构成了一个大粒度的DAG。
在一个Stage内,所有的操作以串行的Pipeline的方式,由一组Task完成计算。
Task
对一个Stage之内的RDD进行串行操作的计算任务。每个Stage由一组并发的Task组成(即TaskSet),这些Task的执行逻辑完全相同,只是作用于不同的Partition。一个Stage的总Task的个数由Stage中最后的一个RDD的Partition的个数决定。
Spark Driver会根据数据所在的位置分配计算任务,即把所有Task根据其Partition所在的位置分配给相应的Executor,以尽量减少数据的网络传输(这也就是所谓的移动数据不如移动计算)。一个Executor内同一时刻可以并行执行的Task数由总CPU数/每个Task占用的CPU数决定,即spark.executor.cores / spark.task.cpus。
Task分为ShuffleMapTask和ResultTask两种,位于最后一个Stage的Task为ResultTask,其他阶段的属于ShuffleMapTask。
Persist
通过RDD的persist方法,可以将RDD的分区数据持久化在内存或硬盘中,通过cache方法则是缓存到内存。这里的persist和cache是一样的机制,只不过cache是使用默认的MEMORY_ONLY的存储级别对RDD进行persist,故“缓存”也就是一种“持久化”。
前面提到,只有触发了一个Action之后,Spark才会提交Job进行真正的计算。所以RDD只有经过一次Action之后,才能将RDD持久化,然后在Job间共享,即如果两个Job用到了相同的RDD,那么可以在第一个Job中对这个RDD进行缓存,在第二个Job中就避免了RDD的重新计算。持久化机制使需要访问重复数据的Application运行地更快,是能够提升Spark运算速度的一个重要功能。
Checkpoint
调用RDD的checkpoint方法,可以将RDD保存到外部存储中,如硬盘或HDFS。Spark引入checkpoint机制,是因为持久化的RDD的数据有可能丢失或被替换,checkpoint可以在这时候发挥作用,避免重新计算。
创建checkpoint是在当前Job完成后,由另外一个专门的Job完成:
也就是说需要checkpoint的RDD会被计算两次。因此,在使用rdd.checkpoint()的时候,建议加上rdd.cache(),这样第二次运行的Job久不用再去计算该rdd了。
一个Job在开始处理RDD的Partition时,或者更准确点说,在Executor中运行的任务在获取Partition数据时,会先判断是否被持久化,在没有命中时再判断是否保存了checkpoint,如果没有读取到则会重新计算该Partition。