题目
请测试LZO的index功能
a) 练习lzo的index如何使用(hadoop-lzo.jar)
b) block是128M,你的lzo数据>128,请使用一个shell造出来这个数据
c) 当做wc的input,观察是否是2个map task
环境
Linux版本: CentOS 6.5
jdk版本: JDK1.8
hadoop版本: 2.6.0-cdh5.7.0
一份数据:page_views.dat 18.1M
linux 有LZO类库:安装LZOM
上传数据
1 | cd ~/data |
放大数据
1 | touch create_data.sh |
将我们的数据放大100倍
1 | !/bin/bash |
运行脚本
1 | sh create_data.sh |

压缩数据
1 | lzop -9v page_big900.dat |

上传到HDFS
1 | hdfs dfs -mkdir /user/hadoop/LZO |

建立索引文件
1 | hadoop jar $HADOOP_HOMOE/share/hadoop/common/hadoop-lzo-0.4.20-SNAPSHOT.jar com.hadoop.compression.lzo.LzoIndexer /user/hadoop/LZO/page_big900.dat.lzo |
1 | hadoop jar $HADOOP_HOMOE/share/hadoop/common/hadoop-lzo-0.4.20-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /home/wyp/input/cite.txt.lzo |
此时会在hdfs目下生成一个index文件

当做WC的input,运行MR作业
当做wc的input,观察是否是以128M为一个split形成一个map task,此次任务按计算应该有 640/128 = 5个
1 | yarn jar /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount \ |
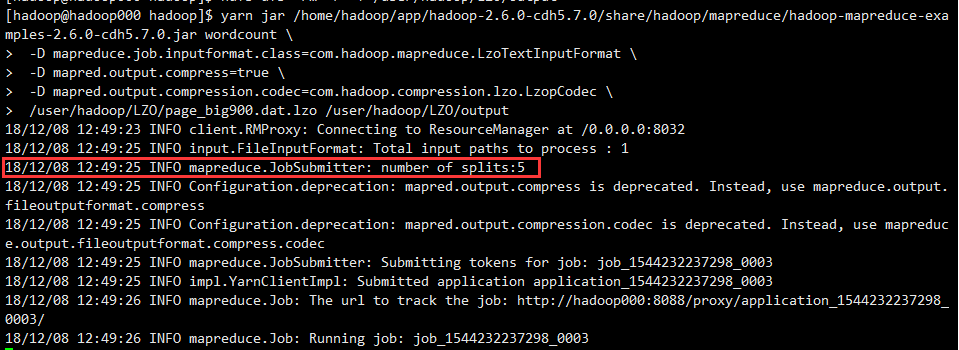
至此,测试完成。