题目
sqoop从mysql导入数据到HDFS,请使用snappy压缩
a) 练习sqoop的用法
b) 安装snappy并整合使用
环境
Linux版本: CentOS 6.5
jdk版本: JDK1.8
hadoop版本: 2.6.0-cdh5.7.0
sqoop版本:1.4.6-cdh5.7.0
hive版本: 1.1.0-cdh5.7.0
mysql版本: 5.6.23
一份数据:page_views.dat 18.1M
检查snappy是否已经安装
1 | hadoop checknative |
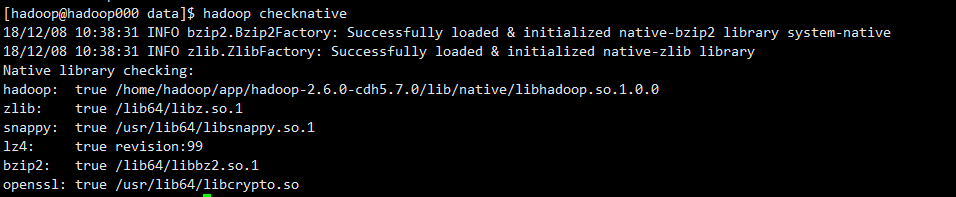
如果你的环境还没有snappy类库请参考编译hadoop源码
创建一张表
在mysql 上面创建一张表用来存放我们的数据
1 | CREATE TABLE sqoop_export_test |
上传数据
1 | cd ~/data |

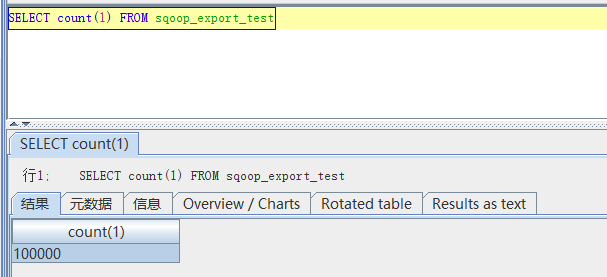
将数据传到mysql
1 | sqoop export \ |
将数据从mysql导入hive
1 | sqoop import \ |
完成
1 | hdfs dfs -ls /user/hadoop/SQOOP_SNAPPY |

1 | hdfs dfs -text /user/hadoop/SQOOP_SNAPPY/part-m-00000.snappy |

至此,我们完成了sqoop从mysql导入数据到HDFS,以sqoop压缩格式导入。