准备工作
- 1.准备好3台虚拟机
- 2.3台虚拟机互信
- 3.准备好安装包
- jdk-8u161-linux-x64.tar.gz
- hadoop-2.6.0-cdh5.7.0.tar.gz
- zookeeper-3.4.12.tar.gz
- 4.Xshell5
新增用户hadoop
在3台虚拟机上面都新建一个hadoop用户
1 | useradd hadoop |
在3台虚拟机上面都新建目录
1 | su - hadoop |
安装JDK
创建jdk存放路径
1 | mkdir -p /usr/java |
上传jdk压缩包
1 | rz |
解压jdk压缩包
1 | tar -xzvf jdk-8u161-linux-x64.tar.gz |
传输到其他两台
1 | scp -r jdk1.8.0_161 root@hadoop002:/usr/java |
修改三台机子上的jdk的持有者
1 | chown -R root:root /usr/java |
配置JDK环境变量
1 | vi /etc/profile |
在文件的末尾加入,以下语句,并保存
1 | env |
使配置生效
1 | source /etc/profile |
查看jdk是否成功安装
1 | java -version |

在另外两台机子也一样做一遍,至此我们的jdk就安装完成了!
集群规划
| IP | HOST | 安装软件 | 进程 |
|---|---|---|---|
| 192.168.137.190 | hadoop001 | Hadoop、Zookeeper | NameNode DFSZKFailoverController JournalNode DataNode ResourceManager JobHistoryServer NodeManager QuorumPeerMain |
| 192.168.137.191 | hadoop002 | Hadoop、Zookeeper | NameNode DFSZKFailoverController JournalNode DataNode ResourceManager NodeManager QuorumPeerMain |
| 192.168.137.192 | hadoop003 | Hadoop、Zookeeper | JournalNode DataNode QuorumPeerMain NodeManager |
安装ZK
上传压缩包
上传ZK的压缩文件文件到hadoop001的software里面
1 | cd software |
传给另外两台机子
1 | scp ~/software/zookeeper-3.4.12.tar.gz hadoop@hadoop002:/home/hadoop/software/ |
在所有机子上一起运行解压ZK压缩文件到app文件夹里面
1 | cd ~/software |
配置ZK_HOME
1 | vi ~/.bash_profile |
1 | .bash_profile |
1 | source ~/.bash_profile |
修改配置
1 | cd ~/app/zookeeper-3.4.12/conf |

1 | vi zoo.conf |
1 | The number of milliseconds of each tick |
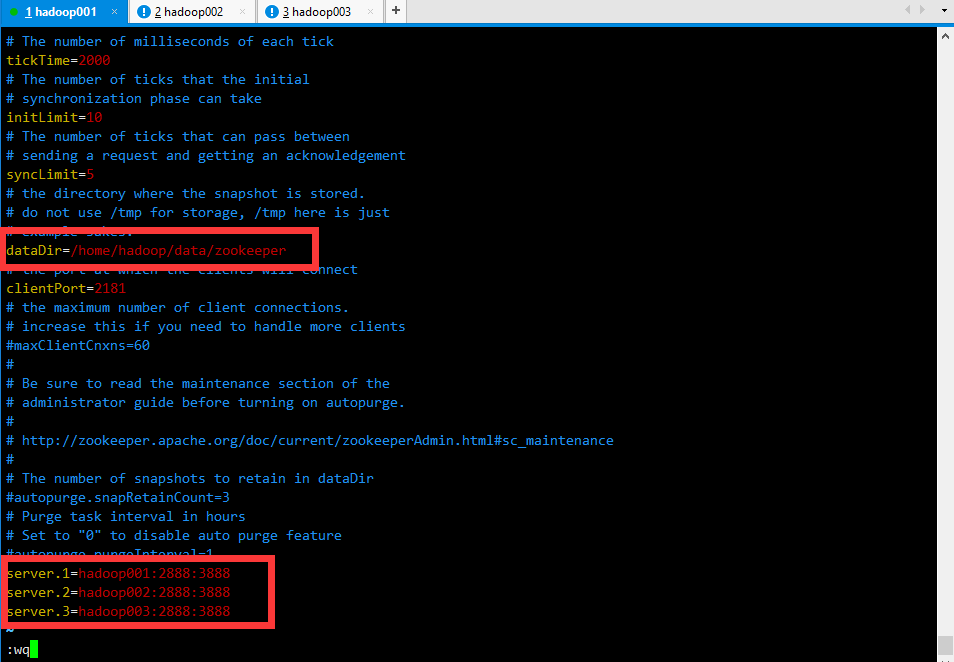
传给其他节点
1 | scp zoo.cfg hadoop@hadoop002:/home/hadoop/app/zookeeper-3.4.12/conf/ |
切换到data目录,并创建一个zookeeper目录
1 | cd ~/data |
在zookeeper目录里面,创建一个myid文件
1 | touch myid |
然后在hadoop001节点上,在myid文件写入1
1 | echo 1 >myid |
在hadoop002节点上,在myid文件写入2
1 | echo 2 >myid |
在hadoop003节点上,在myid文件写入3
1 | echo 3 >myid |
启动集群
1 | zkServer.sh start |
安装Hadoop
上传hadoop的压缩包
在hadoop001机子上使用hadoop用户在software目录上传hadoop的压缩包
1 | cd ~/software |
拷贝到其他两台机子上
1 | scp hadoop-2.6.0-cdh5.7.0.tar.gz hadoop@hadoop002:/home/hadoop/software/ |
解压缩包
三台自己一起执行
1 | cd ~/software |
配置HADOOP_HOME
在hadoop001上面配置一下HADOOP_HOME
1 | vi ~/.bash_profile |
1 | .bash_profile |
1 | source ~/.bash_profile |
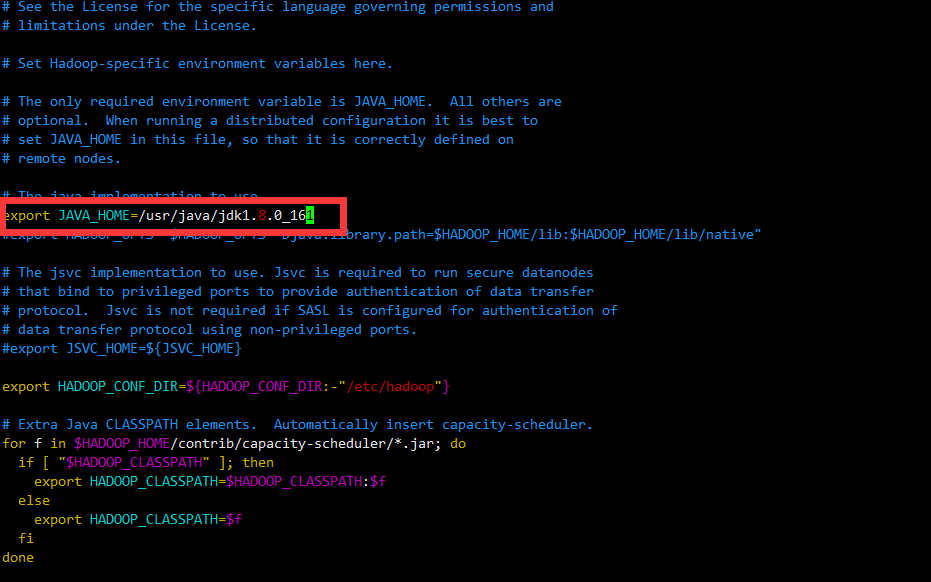
修改hadoop-env.sh
1 | vi /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hadoop-env.sh |
修改core-site.xml
1 | vi /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml |
1 |
|
修改hdfs-site.xml
1 | mkdir -p /home/hadoop/data/dfs/name /home/hadoop/data/dfs/data |
1 |
|
修改/mapred-site.xml
1 | cd ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop |
1 |
|
修改yarn-site.xml
1 | vi /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site.xml |
1 |
|
修改 slaves
1 | [hadoop@hadoop001 hadoop]$ vi slaves |
1 | hadoop001 |
将配置文件传送到其他节点
1 | cd ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/ |
启动JN集群
1 | hadoop-daemon.sh start journalnode |
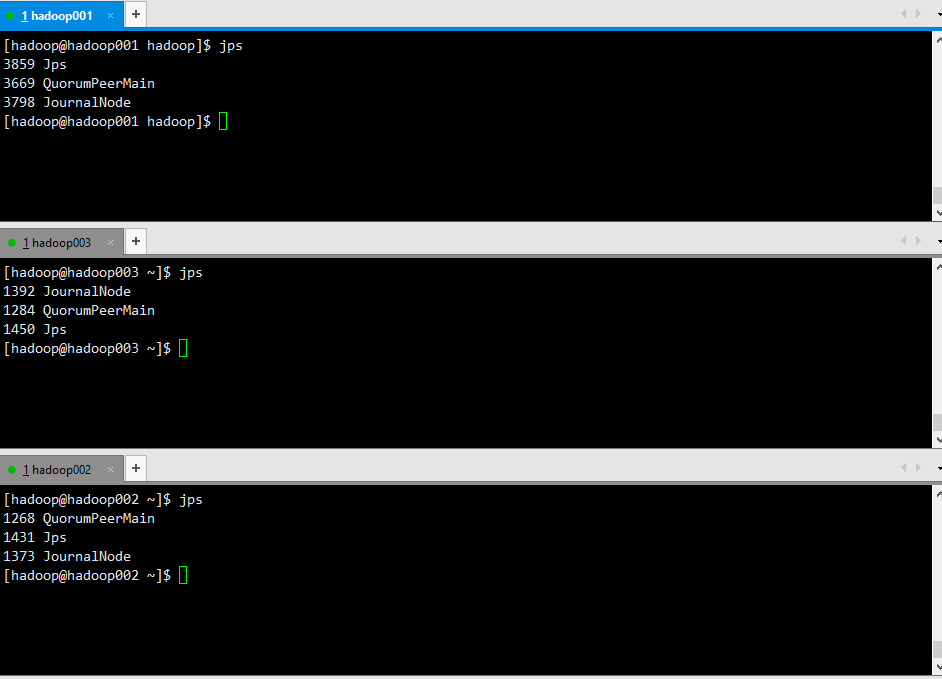
格式化NameNode
在hadoop001节点上输入以下命令
1 | hadoop namenode -format |
1 | DEPRECATED: Use of this script to execute hdfs command is deprecated. |
同步到第二个NN的目录下
1 | scp -r /home/hadoop/data/dfs/* hadoop@hadoop002:/home/hadoop/data/dfs/ |
初始化ZKFC
在hadoop001节点上:
1 | hdfs zkfc -formatZK |
启动HDFS集群
在hadoop001节点上
1 | start-dfs.sh |
检查一下
1 | jps| grep -v Jps |

启动YARN
在hadoop001节点
1 | start-yarn.sh |
在hadoop002节点启动RN(standby)
1 | yarn-daemon.sh start resourcemanager |
检查一下
1 | jps| grep -v Jps |
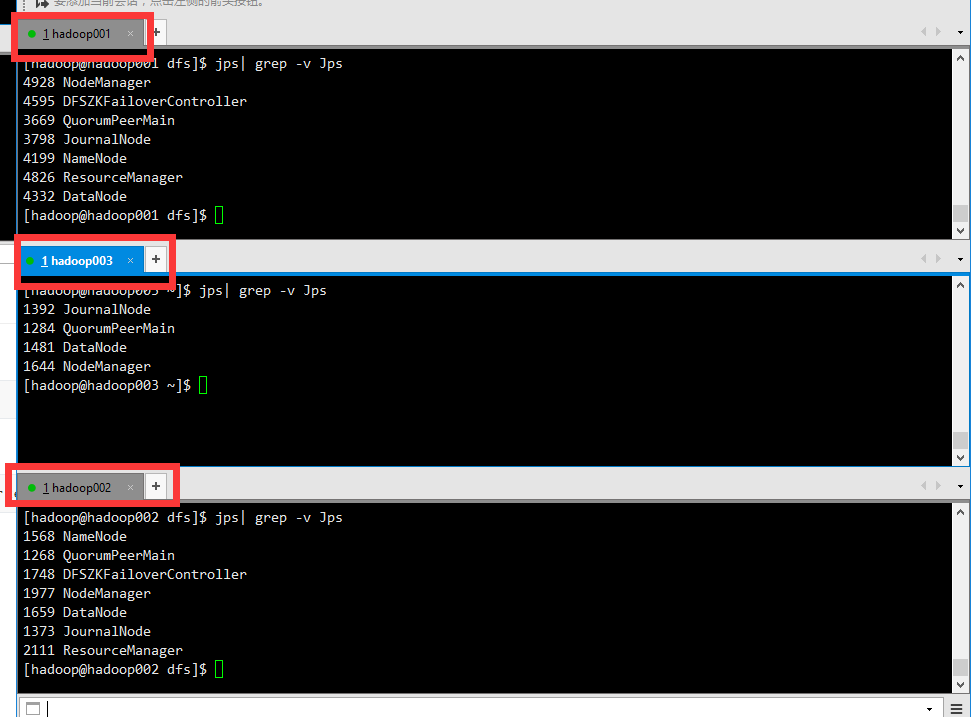
至此我们集群的搭建就完成了。
关闭集群
在hadoop001上
1 | stop-yarn.sh |
在hadoop002上
1 | yarn-daemon.sh stop resourcemanager |
在hadoop001上
1 | stop-dfs.sh |
在三个节点上
1 | zkServer.sh stop |
再次启动集群
在三个节点上
1 | zkServer.sh start |
在hadoop001上
1 | start-dfs.sh |
在hadoop001上
1 | start-yarn.sh |
在hadoop002上
1 | yarn-daemon.sh start resourcemanager |
监控集群
在hadoop001上
1 | hdfs dfsadmin -report |
开启步骤整理
- ZK
- NN
- DN
- JN
- ZKFC
- YARN RM(active) NN
- YARN RM(standby)
关闭步骤整理
- YARN RM(active) NN
- YARN RM(standby)
- namenode
- datanode
- journalnode
- zkfc
- ZK